”k折 k-fold k-NN java 机器学习“ 的搜索结果
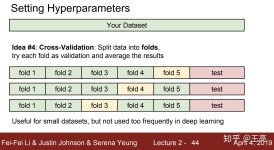
K 折交叉验证(K-flod cross validation) 当样本数据不充足时,为了选择更好的模型,可以采用交叉验证方法。 基本思想:把给定的数据进行划分,将划分得到的数据集组合为训练集与测试集,在此基础上进行反复训练、...
机器学习之k-近邻算法这篇blog对于的源码和数据集

k折交叉验证(k-fold Cross-validation)
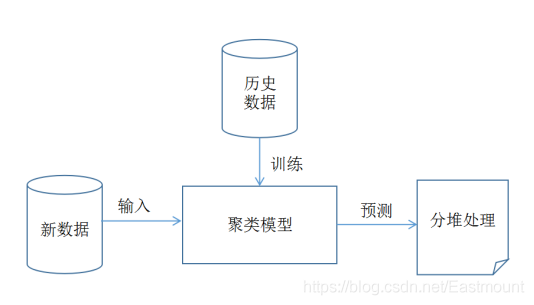
k-means机器学习代码实现,将城市消费消息进行聚类,然后分类。

本文将从k-邻近算法的思想开始讲起,使用python3一步一步编写代码进行实战训练。并且,我也提供了相应的数据集,对代码进行了详细的注释。除此之外,本文也对sklearn实现k-邻近算法的方法进行了讲解。实战实例:电影...
机器学习方法主要分为监督学习方法和非监督学习方法两种。监督学习方法是在样本类别标签已知的条件下进行的,可以统计出各类训练样本的概率分布、特征空间分布区域等描述量,然后利用这些参数进行分类器设计。在实际...

机器学习好伙伴之scikit-learn的使用——K折交叉验证什么是K折交叉验证sklearn中K折交叉验证的实现应用示例 在进行数学建模的时候就听过k折交叉验证,要是我当时像现在一样强就好了! 什么是K折交叉验证 K折交叉...
代码,介绍,数据源,效果展示
本文主要简单介绍了k均值聚类的基本概念,优缺点,应用场景,建模时的注意事项,评价指标,实现方法和示例,以及模型参数等。
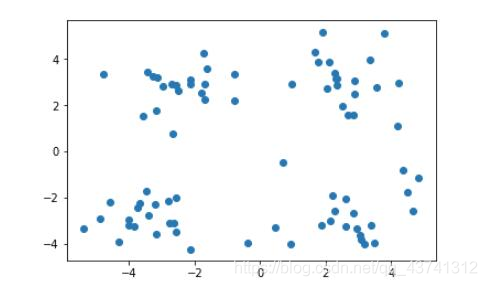

K-Means算法又称K均值算法,属于聚类(clustering)算法的一种,是应用最广泛的聚类算法之一。所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有...K-Means是无监督学习的杰出代表之一。


在机器学习中,我们训练数据集去训练一个model(模型),通常的做法是定义一个Loss function(损失函数),通过这个最小化loss的过程来提高模型的性能。然而我们学习模型的目的是为了解决实际问题(或者说是训练这个数据...

1.K-Means简介 K均值(K-Means)算法是无监督的聚类方法,实现起来比较简单,聚类效果也比较好,因此应用很广泛。K-Means算法针对不同应用场景,有不同方面的改进。我们从最传统的K-Means算法讲起,然后在此基础上...
交叉验证是用来评估机器学习方法的有效性的统计学方法,可以使用有限的样本数量来评估模型对于验证集或测试集数据的效果。 k折交叉验证 参数kkk表示,将给定的样本数据分割成kkk组。k=10k=10k=10时,称为10折交叉...
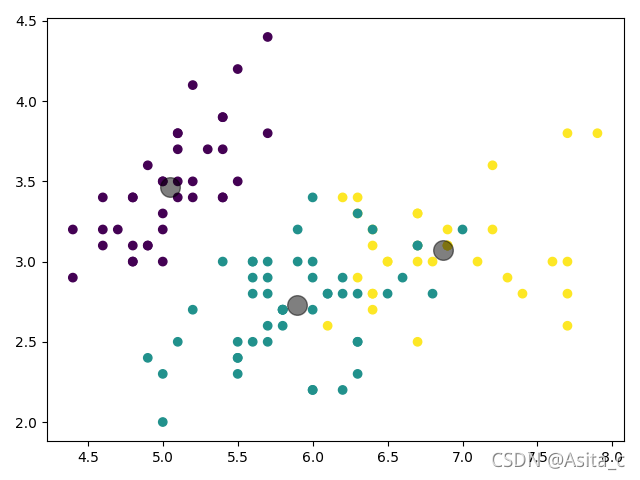
在众多聚类算法中,K-means算法因其简单高效而备受青睐。K-means算法的基本思想是:通过迭代的方式,将数据划分为K个不同的簇,并使得每个数据点与其所属簇的质心(或称为中心点、均值点)之间的距离之和最小。具体...

一、理论准备1.1、图像分割图像分割是图像处理中的一种方法,图像分割是指将一幅图像...1.2、K-Means算法K-Means算法是基于距离相似性的聚类算法,通过比较样本之间的相似性,将形式的样本划分到同一个类别中,K-Mean
文章目录1.实验目的2.导入数据和必要模块3.比较不同模型预测准确率3.1.逻辑回归3.2.决策树3.3.支持向量机3.4....1.实验目的 使用sklearn库中的鸢尾花数据集,并针对以下模型使用cross_val_score来衡量每个模型的性能。...
推荐文章
- Windows系统鼠标右键菜单添加打开cmd终端_we右键进入cmd-程序员宅基地
- python汇编语言还是机器语言_深入理解计算机系统(3.1)------汇编语言和机器语言...-程序员宅基地
- android毕设各种app项目,安卓毕设,android毕设_app毕业设计-程序员宅基地
- Keil侧边工具栏(项目窗口)打开方式_keil侧边栏-程序员宅基地
- 算法学习,转载记录(持续记录)-程序员宅基地
- 局域网探测器_局域网检测-程序员宅基地
- 【C语言基础系列,阿里java面试流程_c语言java面试-程序员宅基地
- Linux技术简历项目经验示例(二)_linux简历工作经验怎么写-程序员宅基地
- 安卓手机软键盘弹出后不响应onKeyDown、onBackPressed方法解决方案-程序员宅基地
- 使用二维数组实现存储学生成绩_c#创建控制台应用程序studentscore,生成学生成绩单——二维数组的使用。-程序员宅基地